AI 辅助研发实践复盘
我从 2022 年底开始关注大模型能力边界。当时 GPT-3.5 刚刚出现,最直接的感受不是“它马上能替代什么工作”,而是不可思议:过去很多需要针对具体任务分别建模、训练和调参的 NLP 问题,突然被统一到一个对话式模型里,并且在相当多任务上表现出了接近甚至超过专用模型的效果。
不过在 GPT-3.5 阶段,我更多还是把它当成新技术现象来观察:它能处理多复杂的问题,在哪些任务上可靠,在哪些地方容易幻觉,代码生成能力到底能走到哪一步。真正让我开始更认真地把大模型放进研发流程,是 2023 年 GPT-4 出来之后。那时它在复杂理解、推理和代码任务上的表现明显更稳定,我才逐步开始用它辅助写脚本、查问题、整理方案和验证一些小工具原型。
这段早期探索的价值不在于”用工具完成了多少工作”,而在于比较早地意识到大模型会改变资料调研、代码理解、原型验证和知识型产品的构建方式。
本文记录的是我这几年跟踪 AI 工具、判断适用边界,并在真实研发问题中验证的过程。
2022 年底:能力边界观察
GPT-3.5 发布初期,我尝试让它处理一些代码相关问题,并在微博记录过相关截图。这类尝试的目的主要是观察模型能力边界,而不是直接把它当成稳定的编程工具:它能理解多长的上下文,能生成多复杂的代码,在哪些地方容易出错,哪些任务仍然需要依赖工程经验、代码审查和人工验证。
同一时期,我也尝试用 Prompt 构建面向论文写作和论文润色场景的 GPTs 工具。这个想法来自刚毕业不久时反复修改论文的经历:很多学术文本并不只是语法问题,还涉及表达清晰度、段落逻辑和写作语气。这个工具实现并不复杂,但在大模型应用早期获得了 300K+ 使用量,说明 Prompt 设计、真实需求判断和快速产品化在当时已经能形成实际价值。
2023-2024 年:进入日常辅助
2023 年 GPT-4 发布后,我开始更稳定地使用 Cursor、GPT、Claude 等工具辅助日常研发,主要用于资料调研、方案对比、问题排查、脚本编写、文档整理和原型验证。
这一阶段我并没有把大模型视为替代工程能力的工具,而是把它作为研发流程中的辅助层:提升调研速度,帮助快速生成初稿,辅助整理上下文,再由人工进行方案判断、代码实现、测试验证和工程化交付。
2023 年上半年,我也开始尝试 GPT-4 和图像生成模型。当时更关注的是能力边界本身:GPT-4 在复杂理解和推理任务上的提升,生图模型在视觉内容生成、风格控制和样本构造上的可能性。
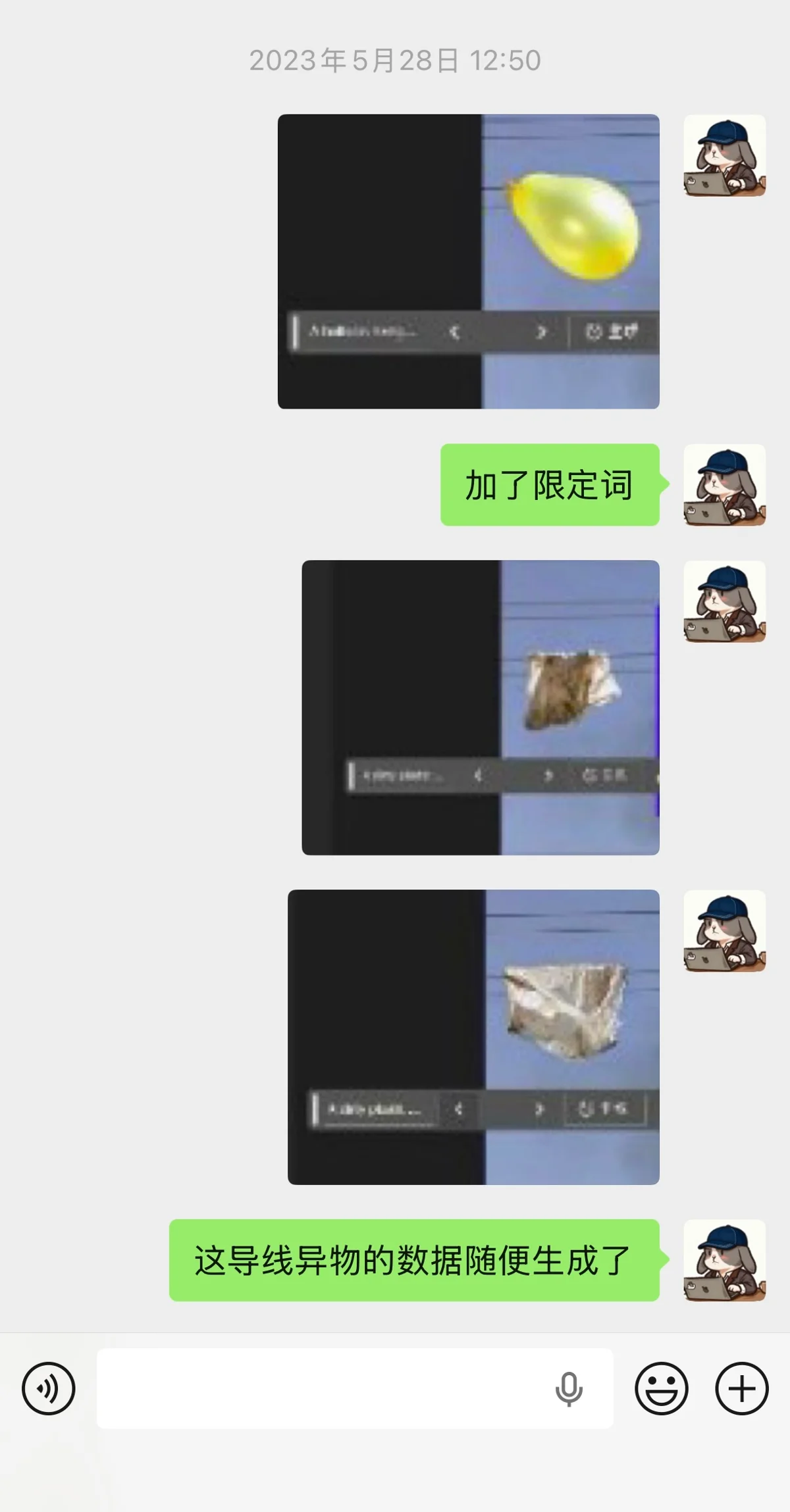
做视觉算法项目期间,我也尝试过使用 Stable Diffusion 生成稀缺缺陷样本,并把生成结果用于项目中的数据增强可行性验证。这个过程让我更早接触到生成式 AI 在算法研发中的另一类价值:它不只是辅助写代码,也可以参与数据构建、样本扩充和方案验证。
我如何跟踪新技术
我平时会关注 Linux Do、V2EX、《科技爱好者周刊》、GitHub 项目、官方文档和开发者实践反馈,用这些信息源观察新工具在真实使用中的边界和问题。
对我来说,关注新技术不是为了追热点,而是先判断它能不能解决手头的具体问题,再选个小场景验证,最后根据效果决定要不要正式用起来。
2025 年底后:Agent 工具成为主要编码辅助方式
2025 年底之后,随着 Claude Code、Codex 等 Agent 工具逐步成熟,我开始把它们作为主要编码辅助方式,用于代码库理解、实现拆解、功能开发、局部重构、测试补全、文档整理和开源项目开发。
在这类任务中,大模型的作用不再只是生成局部代码,而是可以深度参与从理解需求、阅读代码、拆解任务到实现和验证的完整过程。但最终交付质量还是取决于工程判断:是否理解业务目标,是否能审查模型输出,是否能验证结果,以及是否能在现有系统约束下做出可靠实现。
我的判断
AI 编程工具的价值是放大工程师在调研、验证、实现、测试和文档整理上的效率,不是替代工程师。工具越强,对使用者的工程判断、验证意识和上下文组织能力要求反而越高。
Agent 工具成熟后,个人开发者的能力边界被明显拓宽了。很多过去需要团队协作或大量时间投入的功能,现在可以通过更快的代码调研、任务拆解和迭代验证完成。对我来说,当前更大的挑战不再只是实现能力,而是怎么识别真正有价值的需求,并把想法转化为稳定、可维护、可交付的产品。
回看这几年的实践,我比较看重的是技术敏感度和验证意识:新工具刚出现时先判断它能解决什么问题,再在真实场景中小规模验证,最后根据效果决定是否正式采用。Prompt 原型、Stable Diffusion 合成样本、Cursor 辅助研发、Agent 编程工具,走的都是同一条路:用新技术解决手头的具体问题,而不是为了追热点。